End-to-End Proving (Under Development)
Currently under development, this documentation will be continually updated.
Overview
The End-to-End experiment aims to provide an implementation of the abstract AI-ITP setup.
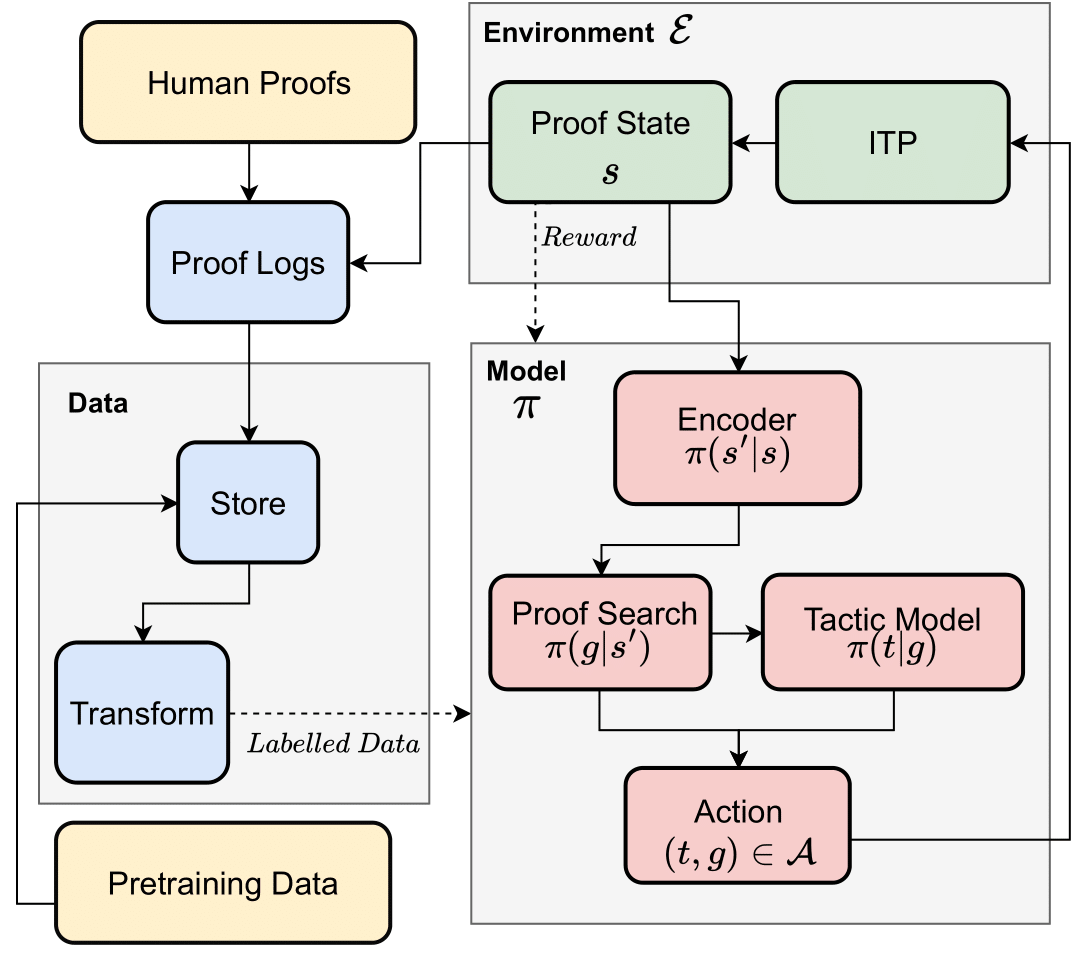
It is designed to be modular, allowing for different combinations of Tactic and Search models to be run on
different Environments with minimal effort. Code associated with this experiment is found in experiments/end_to_end.
An End-to-End experiment works as follows:
- It takes as input the Tactic Model, Search Model and Environment specified in a Hydra config file.
- It then runs the specified models on proofs in the environment, which we call evaluation, and collects a proof log from each attempt.
- Following this, user specified Lightning experiments are run with the new proof logs.
- These experiments are expected to use the newly generated data to train one or both of the Tactic and Search models.
- The newly trained models are then loaded and the process is repeated.
It provides the following features:
- Abstract interface, allows for different Environments, Tactic and Search models to be combined with minimal effort
- Tactic, Search and Environment interfaces are modular and can be extended easily
- Distributed evaluation and training, adapting to the resources available (as specified in the configuration file)
- Automated logging with WandB
- Automatically generates proof traces in a standardised format
- Interactive visualisation of proof attempts
Given the large scope of the project, there may be some bugs or incomplete features. We are working to address these, as well as integrate new Tactic, Search and Environment modules over time.
That being said, the current implementation has proven to be effective in training and evaluating several Tactic and Search approaches across different Environments. It is also the only fully open source implementation of the AI-ITP loop to date.
The current set of combinations of Models and Environments which can be run are summarised below. Items which are bolded have not yet been extensively tested.
Models
Models are located in models/end_to_end/, with search models in search_models and tactic models in tactic_models.
Tactic/Search models with Lightning
Both tactic and search models are assumed to be implemented as Lightning Modules.
For training, they should each have an associated DataModule.
This should define how to process proof traces before training. For
example, models/end_to_end/search_models/goal_model
labels all proven nodes as 1, and all unproven goals over a visit count threshold as 0 (used in HTPS and Fringes).
models/end_to_end/tactic_models/dpo implements Direct Preference Optimisation, ranking edges based on errors and
proofs. models/end_to_end/tactic_models/generator just takes a seq2seq loss over proven (sub)goals.
Search Models
Search models are located in models/end_to_end/search_models/.
Search models should implement a reset method, which resets the state of the search model, a
get_goal method, which returns the chosen goal node to attempt, and a process_response method, which updates the
state of the search model based on the response from the environment. They should also include and update
a search_trace attribute, which is used to visualise and analyse the proof search.
Some search models may also require retraining, and so should implement a separate directory for the Lightning
experiment, as well as a DataModule for processing proof traces before training (as done in tactic models).
An example of this is the HTPS model, which uses a goal model trained in the goal_model directory. The DataModule
labels all proven nodes as 1, and all unproven goals over a visit count as 0, and the model is trained to score goals
based
on this.
- Best First Search (BestFS)
- HyperTree Proof Search (HTPS)
- Breadth First Search (BFS)
- Fringe
Tactic Models
Tactic models are located in models/end_to_end/tactic_models/.
The file tac_models.py is the entry point for adding new models and preparing them for use in the End-to-End
experiment.
Tactic models need to implement a get_tactic method which maps a string to a tactic.
Aside from this, the models have few restrictions.
Most tactic models have an associated DataModule, which defines how to process proof traces before training, as well as
an associated LightningModule which defines the model architecture and training loop. For
example, the generator directory takes
all proven nodes as a 1, and all unproven goals over a visit count as 0, and trains using a seq2seq loss over proven
(sub)goals.
Generative models based on ReProver
The file gen_tac_model.py contains the abstract class for generative models.
Currently these are pre-trained models based on ReProver, extended to support fine-tuning with synthetic data.
-
Currently only trained/tested with LeanDojo Environment
-
Fine-tuning with the following approaches:
- seq2seq
- DPO (Direct Preference Optimisation)
- ILQL (Implicit Lanuage Q-Learning)
Original HOList Tactic Models
The directory holist_model provides a re-implementation of the original HOList model in the End-to-End framework.
- Supports varying embedding architectures (GNN, Transformer, SAT, Directed SAT, Ensemble)
- Currently only tested on the HOList environment, using the fixed tactic set from the original HOList as well as s-expression parsing
TacticZero based model
The directory tacticzero provides a re-implementation of the original TacticZero model in the End-to-End framework.
- Incorporates the TacticZero tactic/argument generation architecture.
- Only tested so far with HOL4, using the fixed tactic set from the original TacticZero.
- Currently only implemented for evaluation, training is not yet supported.
- To add this, logs from the proof search would need to be processed for policy gradient (if replicating the original TacticZero approach), or to a new approach (e.g. supervised training)
Environments
New environments should be added under environments/ and should implement the following methods to be used in the
End-to-End experiment:
__init__(thm, timeout)(initialises the environment with an environment specific thm object)__enter__(starts the environment)__exit__(closes the environment)retrieve_premises(returns the allowed premises of the current goal)run_tactic(runs a tactic in the underlying environment on a selected goal, updates the proof tree and returns the response)
The following environments are currently supported for End-to-End experiments:
- LeanDojo (
environments/LeanDojo/lendojo_env.py) - HOList (
environments/HOList/holist_env.py) - HOL4 (
environments/HOL4/hol4_env.py)
Additional documentation for the environments can be found here.
Running
End-to-End experiments can be run using the following command:
python3 -m experiments.end_to_end.end_to_end_experiment --config-name=<config_name>
Where <config_name> is the name of the Hydra configuration file to use, as detailed below.
Configuration
The End-to-End experiment is run using Hydra configuration files. These are located in experiments/end_to_end/configs.
A summary of the fields are as below:
# experiment config
exp_config:
name: <name of the experiment>
experiment: <name of the experiment>
resume: <True/False>
directory: <directory to save experiment files, checkpoints and logs>
logging_config:
id: <wandb id>
offline: <True/False>
env_config:
<environment specific configuration>
# whether to shuffle the loaded theorems before evaluation
shuffle: <True/False>
# Number of End-to-End Eval -> Train -> Eval loops
num_iterations: <number of iterations>
resume_iteration: <iteration to resume from>
# Total time allowed for a single proof attempt
total_timeout: <timeout in seconds>
# Maximum time allowed in environment before timing out
env_timeout: <timeout in seconds>
with_gpus: true
log_level: <log level (e.g. INFO, DEBUG, WARNING)>
# Resource configuration
# number of physical GPUs
num_gpus: <number of GPUs>
# how many 'logical' GPUs available, should be a multiple of num_gpus.
# Will control the number of separate tactic/search model processes
logical_gpus: <number of logical GPUs>
num_cpus: <number of CPUs>
# How much GPU memory to allocate per prover (should be low, since the model is using most of the GPU)
gpu_per_prover: <fraction of GPU memory to allocate per prover>
# CPU resources to allocate per prover.
cpu_per_prover: <fraction of CPU resources to allocate per prover>
# How many provers to assign per logical GPU. Each of these provers will share one tactic/search process.
provers_per_gpu: <number of provers per GPU>
# number of tactics to run for each goal
num_sampled_tactics: 64
tac_model:
<tactic model configuration> (e.g. generator, HOList model)
search_model:
<search model configuration> (e.g BestFS, HTPS)
# Commands to run for retraining the model(s) after every evaluation
train_after_eval:
<command 1 to run for retraining model>
<command 2 to run for retraining model> etc.
# e.g. 1 for generator python3 -m experiments.lightning_runner --config-name=end_to_end/train/gen_seq2seq/run data_module.trace_files=${exp_config.directory}/traces
# e.g. 2 for HTPS goal model python3 -m experiments.lightning_runner --config-name=end_to_end/train/goal_model/run data_module.trace_files=${exp_config.directory}/traces
# The model(s) and checkpoint attribute(s) to update.
# Must be same length as train_after_eval, with each index corresponding to the associated command
update_checkpoints:
# e.g.
- [ tac_model, ckpt_path ]
- [ search_model, ckpt_path ]
Examples
The below configurations are some examples of End-to-End experiments:
experiments/configs/end_to_end/holist/holist.yaml- Runs the HOList environment with the original HOList tactic model and the BestFS search model.experiments/configs/end_to_end/leandojo/leandojo.yaml- Runs the LeanDojo environment with the generator tactic model and the BestFS search model.experiments/configs/end_to_end/hol4/hol4.yaml- Runs the HOL4 environment with the TacticZero tactic model and the BestFS search model.
Possible Future Additions
LeanDojo
- Add tactic models which are restricted to a small/fixed subset as done in HOList or TacticZero models.
HOList
- Generative ReProver style model (currently would be restricted by the environment, as outlined in the ~HOList docs)
HOL4
- Generative ReProver style model
- TacticZero training